在iOS原生app中增加ReactNative
- 新建一个iOS的项目,打开XCode,新建一个项目,选择Tabbed App
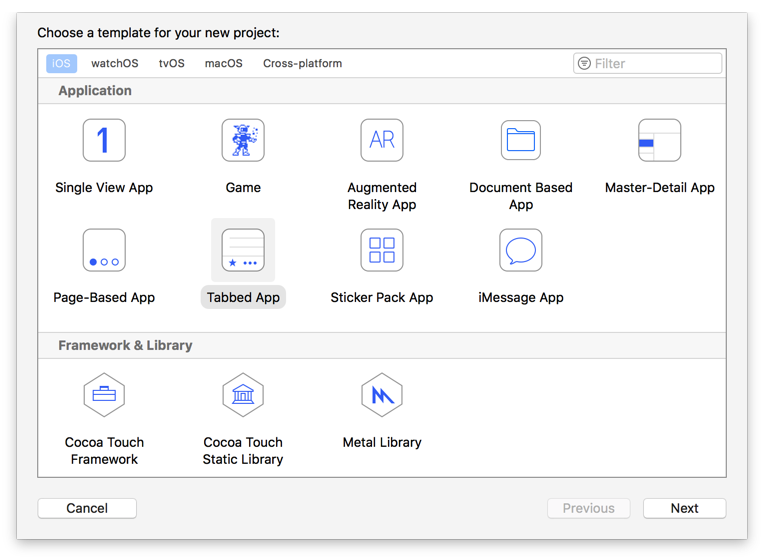
-
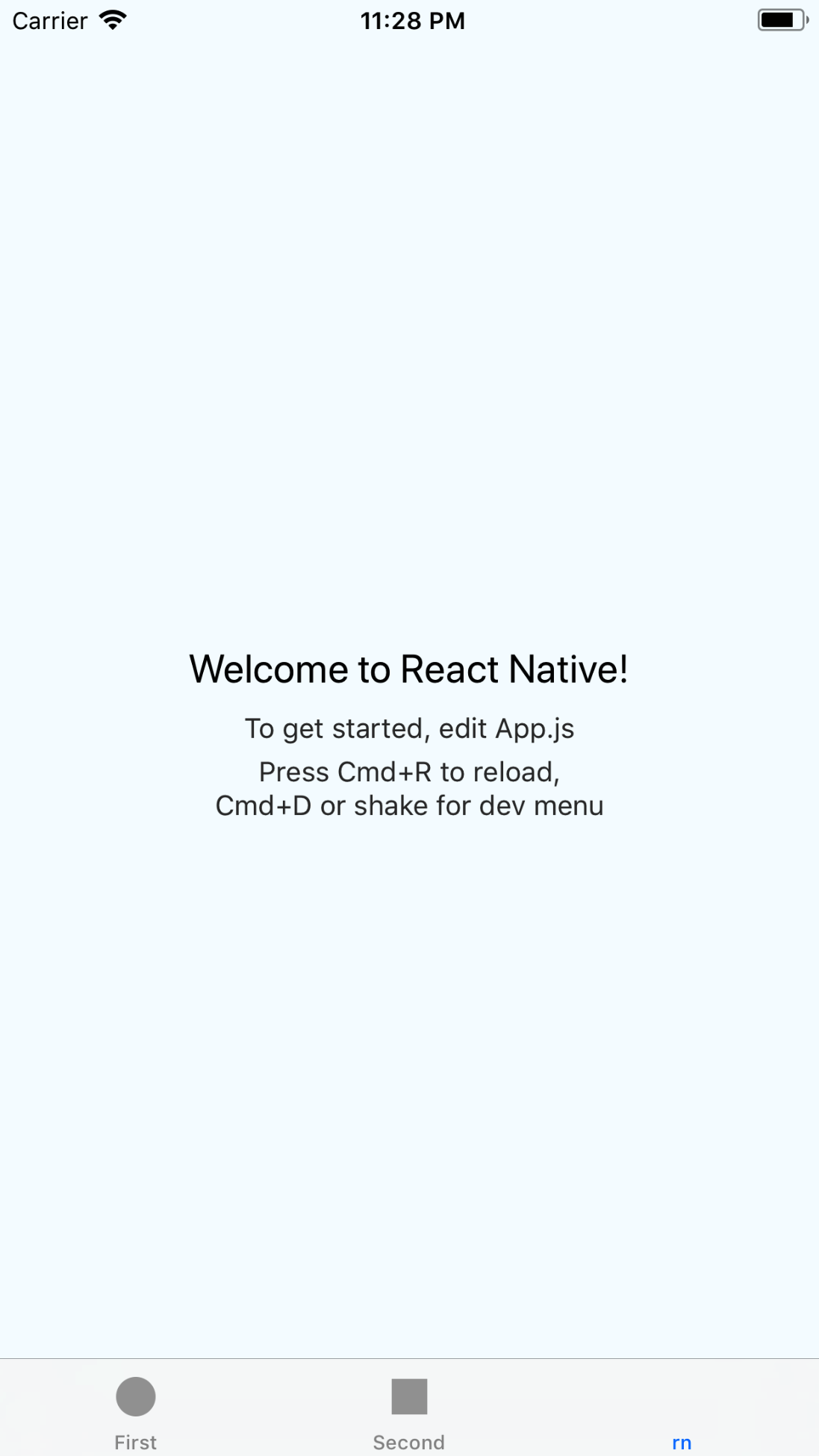
运行一下看看效果

-
新建一个react-native项目,和iOS的项目中同一个目录下
brew install node brew install watchman npm install -g react-native-cli react-native init ReactNativeProject - 启动react-native服务器
react-native start - 安装CocoaPods
brew install cocoapods - 初始化CocoaPods,在你的iOS项目根目录里运行
pod init - 编辑生成的Podfile,增加react-native的pod
# Uncomment the next line to define a global platform for your project # platform :ios, '9.0' target 'demo' do # Comment the next line if you're not using Swift and don't want to use dynamic frameworks use_frameworks! # Pods for demo pod 'React', :path => ‘../ReactNativeProject/node_modules/react-native', :subspecs => [ 'Core', 'CxxBridge', # Include this for RN >= 0.47 'DevSupport', # Include this to enable In-App Devmenu if RN >= 0.43 'RCTText', 'RCTNetwork', 'RCTWebSocket', # needed for debugging # Add any other subspecs you want to use in your project ] pod "yoga", :path => "../ReactNativeProject/node_modules/react-native/ReactCommon/yoga" pod 'DoubleConversion', :podspec => '../ReactNativeProject/node_modules/react-native/third-party-podspecs/DoubleConversion.podspec' pod 'GLog', :podspec => '../ReactNativeProject/node_modules/react-native/third-party-podspecs/GLog.podspec' pod 'Folly', :podspec => '../ReactNativeProject/node_modules/react-native/third-party-podspecs/Folly.podspec' target 'demoTests' do inherit! :search_paths # Pods for testing end target 'demoUITests' do inherit! :search_paths # Pods for testing end end - 运行
pod install安装依赖,得到以下输出:$ pod install Setting up CocoaPods master repo $ /usr/bin/git clone https://github.com/CocoaPods/Specs.git master --progress Cloning into 'master'... remote: Counting objects: 1799117, done. remote: Compressing objects: 100% (377/377), done. remote: Total 1799117 (delta 157), reused 35 (delta 35), pack-reused 1798692 Receiving objects: 100% (1799117/1799117), 500.73 MiB | 320.00 KiB/s, done. Resolving deltas: 100% (981561/981561), done. Checking out files: 100% (203691/203691), done. Setup completed Analyzing dependencies Fetching podspec for `DoubleConversion` from `../ReactNativeProject/node_modules/react-native/third-party-podspecs/DoubleConversion.podspec` Fetching podspec for `Folly` from `../ReactNativeProject/node_modules/react-native/third-party-podspecs/Folly.podspec` Fetching podspec for `GLog` from `../ReactNativeProject/node_modules/react-native/third-party-podspecs/GLog.podspec` Fetching podspec for `React` from `../ReactNativeProject/node_modules/react-native` Fetching podspec for `yoga` from `../ReactNativeProject/node_modules/react-native/ReactCommon/yoga` Downloading dependencies Installing DoubleConversion (1.1.5) Installing Folly (2016.09.26.00) Installing GLog (0.3.4) Installing React (0.51.0) Installing boost (1.59.0) Installing yoga (0.51.0.React) Generating Pods project Integrating client project - 打开iOS项目目录下的demo.xcworkspace
-
在AppDelegate.swift文件中引入React
import React - 声明react-native组件的UIViewController并加入到tab中
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool { // Override point for customization after application launch. var tab = self.window?.rootViewController as! UITabBarController let jsCodeLocation = URL(string: "http://localhost:8081/index.bundle?platform=ios") let rootView = RCTRootView( bundleURL: jsCodeLocation, moduleName: "ReactNativeProject", initialProperties: nil, launchOptions: nil ) let vc = UIViewController() vc.view = rootView vc.title = "rn" tabbar.viewControllers?.append(vc) return true } - 设置允许localhost的http访问
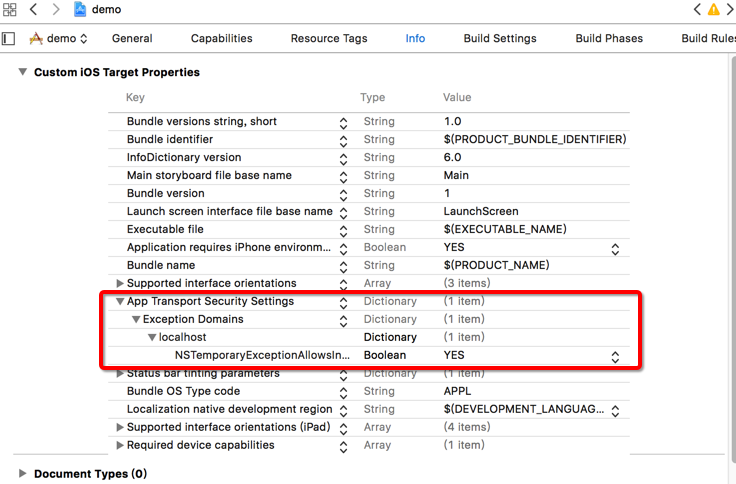
-
运行看看效果